导读
本篇文章主要是为了宣导 GraphQL 技术,包含了介绍 GraphQL 能解决的问题和尚不完善的地方,以及我们团队在实际业务场景中的实践总结。希望读者能通过这篇文章,了解到 GraphQL 的优缺点,在遇到合适的场景中能多一个技术选择,并在日后的实践过程能有所参考,避免重复踩坑。
背景
目前在我们绝大多数的场景中,后端提供的接口是基于 RESTful 风格的接口,而 RESTful 架构风格的服务是围绕资源展开的。随着业务复杂度的提高,前端页面信息和交互体验的愈加复杂,RESTfull风格的接口,在实际研发场景下,通常会遇到以下几处痛点:
1.性能瓶颈
后端往往是采取微服务架构,拆分成多个服务,一个页面往往需要发送多个请求,才能获取足够的数据。而对于同一个接口,如果参数有多种组合,也需要调用多次才可。
请求的数量愈多,以下的耗时愈多:
- 队列等待时间(浏览器对同一个主机域名的并发连接数有限制)
- 链接建立和销毁耗时
- 后端重复的权限或参数校验
- 客户端与服务器之间来回响应时间
2.数据冗余
后端提供的接口,通常会在多个场景(或页面)中使用,后端同学无法事先预知前端需要哪些数据,因此基本都是返回大而全的信息,宁多勿缺。随着业务的发展,会加入更多的数据,而且为了保持兼容性,基本只增不减。
3.文档缺失
文档跟接口分离,无法直观通过接口或者单个文档获取所有需要的接口信息。同时,文档很难与实现完全保持一致,基本依靠人工来保证信息的准确性和及时性,不可靠。
简介

作为 Facebook 在 2015 年推出的查询语言,GraphQL 能够对 API 中的数据提供一套易于理解的完整描述,使得前端能够更加准确的获得它需要的数据,目前包括 Facebook、Twitter、GitHub 在内的很多公司都已经在生产环境使用 GraphQL 提供 API。
以下是官方对 GraphQL 的定义
GraphQL 既是一种用于 API 的查询语言也是一个满足你数据查询的运行时。 GraphQL 对你的 API 中的数据提供了一套易于理解的完整描述,使得客户端能够准确地获得它需要的数据,而且没有任何冗余,也让 API 更容易地随着时间推移而演进,还能用于构建强大的开发者工具。
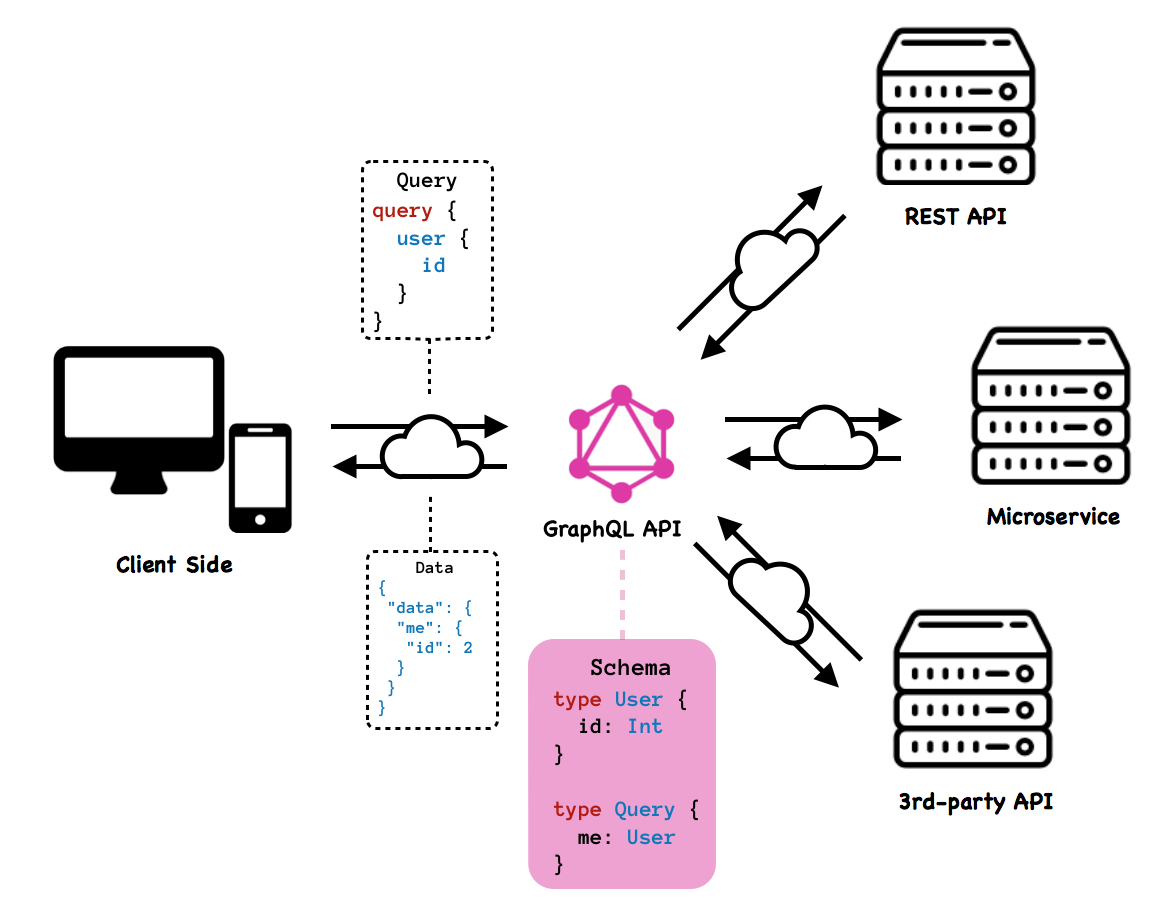
GraphQL 的强大表达能力主要还是来自于它完备的类型系统,与 REST 不同,它将整个 Web 服务中的全部资源看成一个有连接的图,而不是一个个资源孤岛,在访问任何资源时都可以通过资源之间的连接访问其它的资源。
举个例子,假如我们有以下的结构
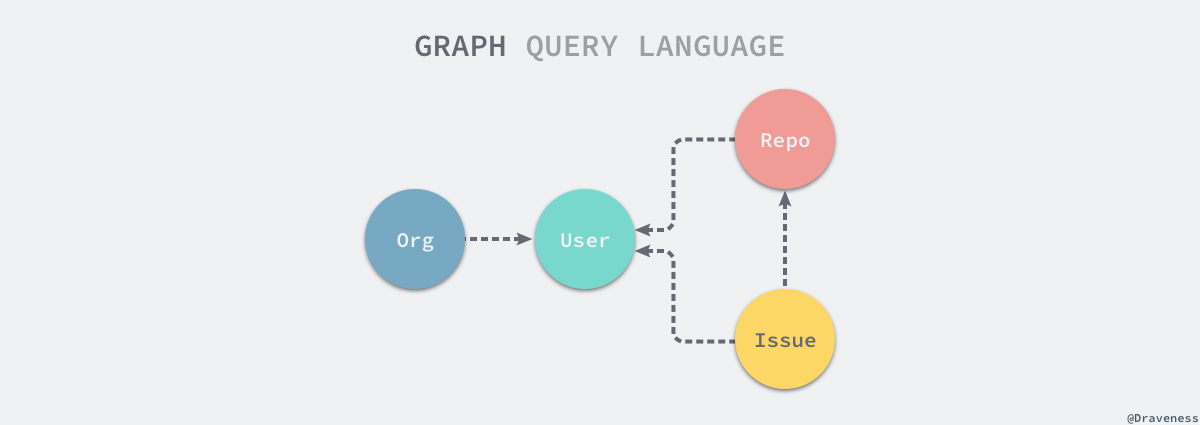
当我们访问 User 资源时,就可以通过 GraphQL 中的连接访问当前 User 的 Repo 和 Issue 等资源,我们不再需要通过多个 REST 的接口分别获取这些资源,只需要通过如下所示的查询就能一次性拿到全部的结果:
1 | { |
GraphQL 这种方式能够将原有 RESTful 风格时的多次请求聚合成一次请求,不仅能够减少多次请求带来的延迟,还能够降低服务器压力,加快前端的渲染速度。
此外,它的类型系统也非常丰富,除了标量、枚举、列表和对象等类型之外,还支持接口和联合类型等高级特性。
对比
与 RESTful 最明显的不同,是每一个的 GraphQL 服务其实对外只提供了一个用于调用内部接口的端点,所有的请求都访问这个暴露出来的唯一端点。

GraphQL 实际上将多个 HTTP 请求聚合成了一个请求,它只是将多个 RESTful 请求的资源变成了一个从根资源 Post 访问其他资源的 Comment 和 Author 的图,多个请求变成了一个请求的不同字段,从原有的分散式请求变成了集中式的请求,这种方式非常适合单体服务直接对外提供 GraphQL 服务,能够在数据源和展示层建立一个非常清晰的分离,同时也能够通过一些强大的工具,例如 GraphiQL 直接提供可视化的文档。
优点
1.数据的关联性和结构化更好
RESTful 所操作的资源相对是离散的;而 GraphQL 的数据更有整体性。
举个例子,如果要获取 A 的朋友的朋友,用 RESTful 该怎么做呢?
假设我们有这样一个接口:
1 | GET /user/:userId/friends/ |
而 A 有 20 个好朋友,那么我们总共需要发送 20 + 1 = 21 次 REST 请求。
为了减少请求数量,为了这种特殊场景,通常会设计出以下这种接口:
1 | GET /user/:userId/friendsAndHisFriends/ |
而这种情况如果是在 GraphQL 中,会怎么做呢?
首先我们需要给 User 定义 Schema (GraphQL 有一套完整的类型系统):
1 | type User { |
假设我们在 Graph root 上只挂了一个 Node,叫 user:
1 | type Query { |
那么我们从客户端发送的 query 就可以写成这样:
1 | query ($userId: ID) { |
通过这一个请求就可以完成查询朋友的朋友这种头疼的需求。
2.精准地数据获取
- 声明式 (Declarative) 获取数据,非常直观和精准
- 可以自主控制需要获取的数据,数据刚刚好,不多也不少
- 数据模型之间可以建立连接关系,大幅減少来回请求的数量
相比之下 RESTful API 就需要来回多次才能够获取足够的数据,并且大多数情况下会携带额外的数据,缺乏弹性 (multiple round-trips) 。
3.代码即文档
能够有效减少前后端的沟通成本,建立文档的时间成本基本为0。
4.提高前端控制权
以前为了适应不同的平台或者不同版本的需要,需要新开API,或者API中做平台/版本判断来控制返回值
而 GraphQL API 则只需要一套API,由前端开发来决定需要获取那些数据,并且可以预期对返回的数据的格式和内容
5.高度自由的实现方式
不依赖于某种语言,GraphQL 让你的整个应用共享一套 API,而不用被限制于特定存储引擎。GraphQL 引擎已经有多种语言实现,通过 GraphQL API 能够更好利用你的现有数据和代码。你只需要为类型系统的字段编写函数,GraphQL 就能通过优化并发的方式来调用它们。
6.强类型 (Strongly Typed)
一切面向前端的接口都有强类型的 Schema 做保证,且完整类型定义因 introspection 完全对前端可见,一旦前端发送的 query 与 Schema 不符,能快速感知到产生了错误。
支持五种基础类型 (Scalar Types),以及自定义类型
不足
1.学习成本
- 如果要应用到整个公司或者基础架构上,仍需要时间来推广和谨慎的技术方案讨论
- 很容易就会陷入 RESTful API 设计思维,埋下技术债
- 很多处理方式,如执行效率、错误处理、权限控制等,需要额外的学习
2.缺少官方实现
目前 FB 官方就只有一个 Node.js 的 reference implementation,其他语言都是社区爱好者自己搞的。另外,GraphQL 在前端如何与视图层、状态管理方案结合,目前也只有 React/Relay 这个一个官方方案。
3.过于自由、规范少
- 没有一个成熟的Best Practice时,容易出现Anti Pattern
- 没有一定的设计规范,容易设计出过于复杂的Scheme
在实现 GraphQL 服务端接口时,很容易就会写出效率极差的代码,引起 “N+1 问题”。GraphQL 的 field resolve 如果按照 naive 的方式来写,每一个 field 解析都执行一遍数据库的话,会产生大量冗余 query,虽然网络层面的请求数被优化了,但数据库查询可能会成为性能瓶颈,这块虽然可以优化,但并不是那么容易做。
数据库层面的 N + 1 查询我们可以通过减少 SQL 查询的次数来解决,一般我们会将多个 = 查询转换成 IN 查询;但是 GraphQL 中的 N + 1 问题就有些复杂了,尤其是当资源需要通过 RPC 请求从其他微服务中获取时,更不能通过简单的改变 SQL 查询来解决。
目前业界常用的解决方案是通过使用了 DataLoader 从业务层面解决了 N + 1 问题,其核心逻辑就是整合多个请求,通过批量请求的方式解决问题。
DataLoader is a generic utility to be used as part of your application’s data fetching layer to provide a simplified and consistent API over various remote data sources such as databases or web services via batching and caching.
应用
在业务复杂性指数提升的今天,微服务架构成为了解决某些问题时必不可少的解决方案,因此,在实际应用中,如何在微服务架构中使用 GraphQL 提高前后端之间的沟通效率并降低开发成本成为了一个值得考虑的问题。
微服务架构是希望将大服务拆分成多个自恰的微服务,而Graphql 则希望将数据都进行汇集,一个强调拆,一个强调合,其中会有一些碰撞,解决的关键就在于如何设计schema。
从总体来看,微服务架构暴露的 GraphQL 接口应该只有两种:
一种接口是分散式的,每一个微服务对外暴露不同的端点,分别对外界提供服务。
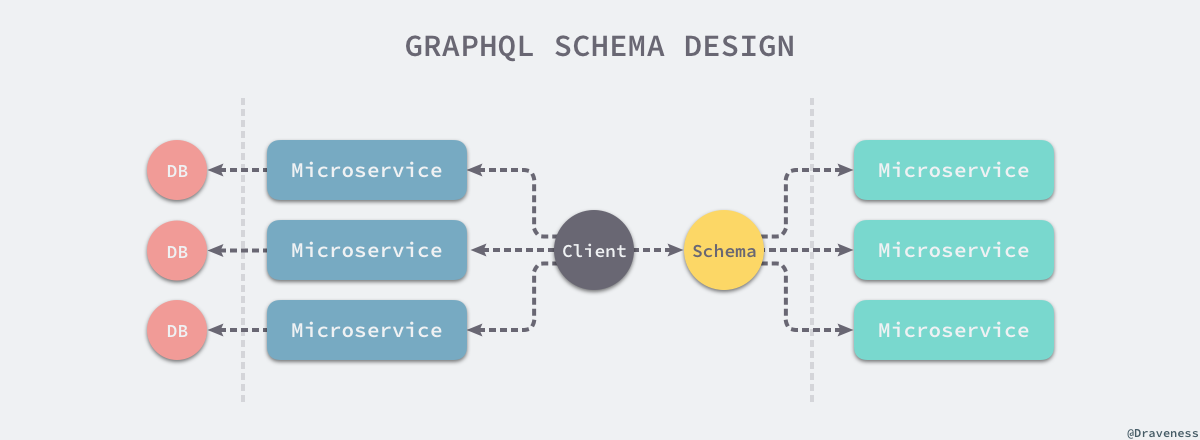
在这种情况下,流量的路由是根据用户请求的不同服务进行分发的,也就是我们会有以下的一些 GraphQL API 服务:
1 | https://draveness.me/posts/api/graphql |
但这种设计其实并没有充分利用 GraphQL 服务的优点,当客户端或前端同时需要多个服务的资源时,需要分别请求不同服务上的资源,并不能通过一次 HTTP 请求满足全部的需求。
另一种方式其实提供了一种集中式的接口,所有的微服务对外共同暴露一个端点,根据请求中不同的字段进行路由。
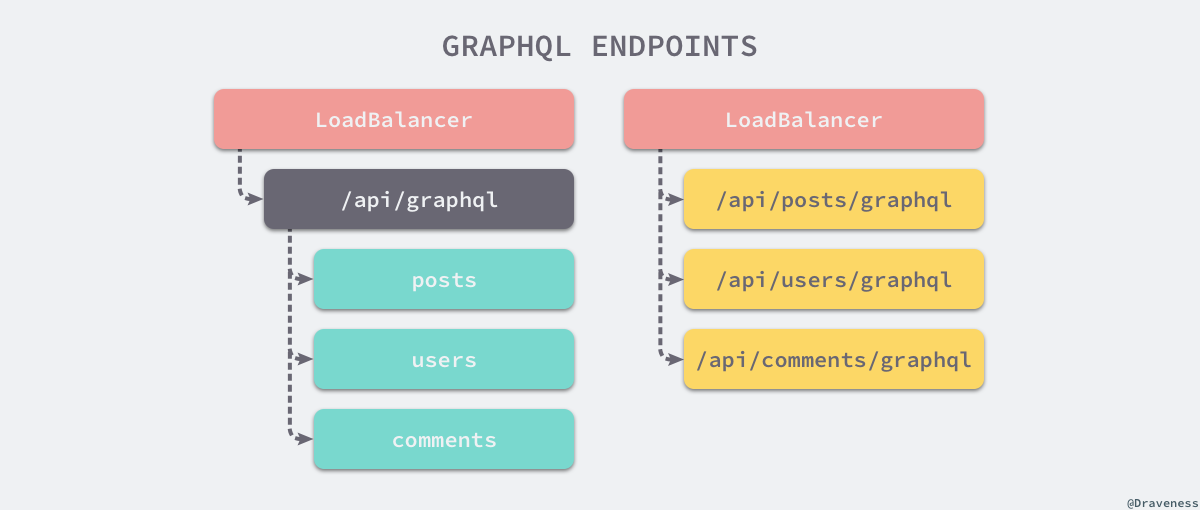
这种方式是按照 field 进行路由的,而 GraphQL 已经帮助我们完成了解析的过程,我们只需要对相应字段实现特定的 Resolver 处理返回的逻辑就可以。
在实践中,作为一门中心化的查询语言,GraphQL 在最佳实践中应该只对外暴露一个端点,并且这个端点包含当前 Web 服务应该提供的全部资源,并把它们合理的连接成图,因此第二种方式更加合理。
然而这种方式,需要思考如何解决在整合 Schema 的过程中服务之间的重复资源和冲突字段问题,需要找到一种机制将多个服务的 Schema 完美整合起来。
目前业界主要有以下解决方式:
1)前缀
为多个服务提供的资源添加命名空间,一般来说就是前缀,在合并 Schema 时,通过添加前缀能够避免不同服务出现重复字段造成冲突的可能。
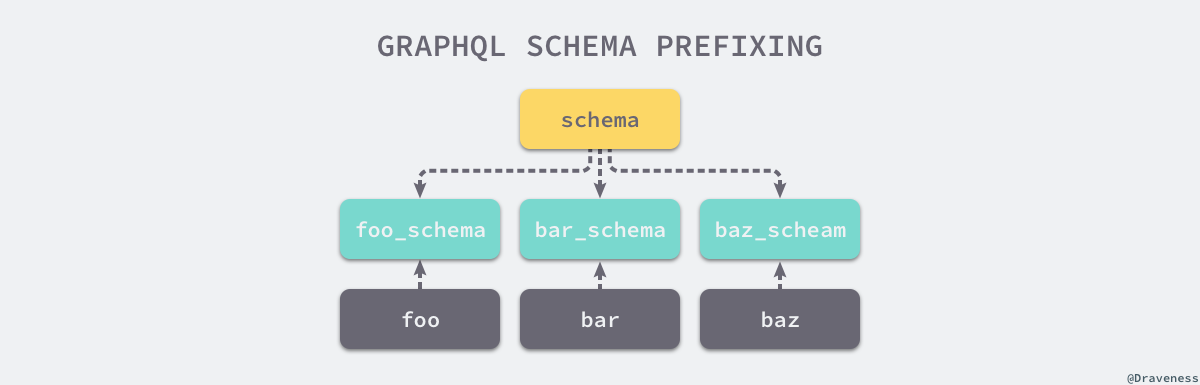
感兴趣的可以阅读 GraphQL at massive scale: GraphQL as the glue in a microservice architecture 了解这种做法的实现细节。这种增加前缀解决冲突的方式优点就是开发成本非常低,但是它将各个微服务的资源看成是一个个的孤岛,资源相互之间没有办法建立关系,串联起来。
2)粘合
GraphQL 官方提供了一种名为 Schema Stitching 的方案,能够将不同服务的 GraphQL Schema 粘合起来并对外暴露统一的接口,这种方式能够将多个服务中的不同资源粘合起来,能够充分利用 GraphQL 的优势。
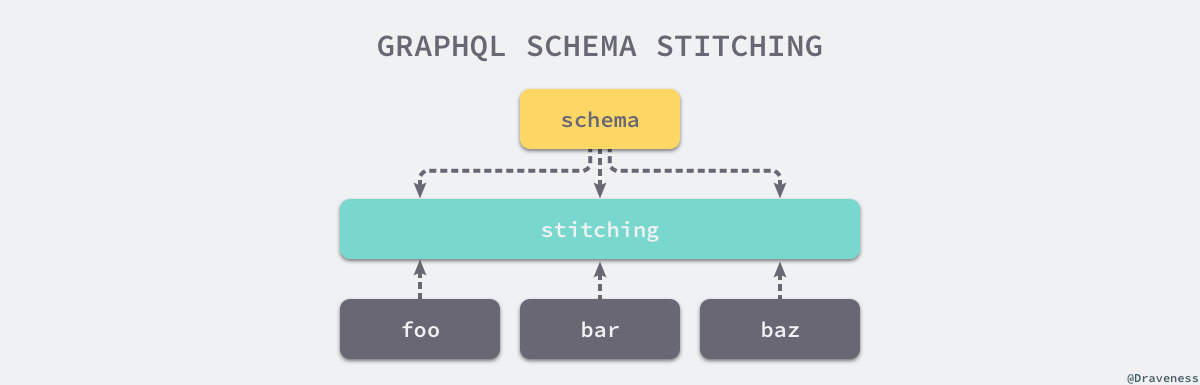
这种方式,需要我们在上层完成对公共资源的处理。当整个 Schema 进行合并时,如果遇到公共资源,就会选用特定的 Resolver 进行解析,而这些解析器的逻辑是在 Schema Stitching 时指定的。
官方提供了一个实现方式,就是通过方法 mergeSchemas ,其详情可以参看 https://www.apollographql.com/docs/apollo-server/api/graphql-tools.html#mergeSchemas 。
方法 mergeSchemas 接受三个参数,需要粘合的 Schema 数组、多个 Resolver 以及类型出现冲突时的回调:
1 | mergeSchemas({ |
实践
我们团队在实践中,项目主要是通过 Koa + Apollo Server + Dataloader + RPC 进行搭建。
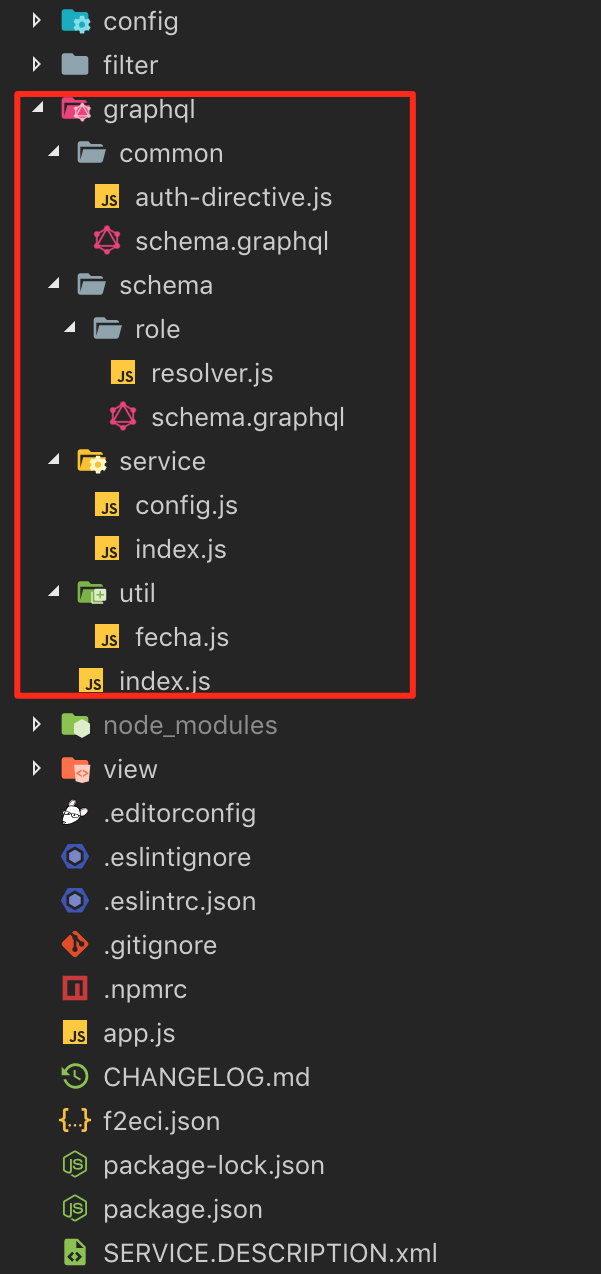
目录结构
项目的目录结构如下,其中
- graphql:存放所有graphql文件
- common:存放通用的schema、directive
- schema:业务逻辑(各业务模块:每个业务模块包含一个resolver.js和schema.graphql文件)
- service:后端RPC服务,使用dataloader封装后端RPC服务,提供统一服务
- util:工具类
- index.js:聚合所有schema文件
Schema
为了减小重复代码,schema可以按照模块化的方式进行划分,可抽离公共的schema,如下
1 | "分页信息" |
在业务 schema 需要使用公共 schema的时候,通过 import 的方式进行引入
1 | \# import PageInfo from "../common/schema.graphql" |
最后可通过以下方式进行集成
1 | const { makeExecutableSchema } = require('graphql-tools'); |
数据请求
强烈建议通过RPC服务调用后端接口,而不是http服务,以减少请求的耗时。
鉴权
身份鉴权,有两种方式:全局和局部
全局
在入口处,也即 context 回调中,进行全局的鉴权
1 | // app.js |
局部
如果要实现局部鉴权(个别字段才需要鉴权),可以通过directive来控制
1)创建一个鉴权的directive,可参考以下代码
1 | const { SchemaDirectiveVisitor } = require('graphql-tools'); |
2)在schema中,需要鉴权的字段进行引用
1 | directive @auth on FIELD_DEFINITION |
3)在 makeExecutableSchema 时,添加 schemaDirectives ,如下
1 | const schema = makeExecutableSchema({ |
效果展示
Apollo Server集成了graphiql,可以很方便的测试接口,所见即所得,而且可以随时展开右侧的API文档,即时查阅所有的接口,包括参数信息和返回数据,一目了然。
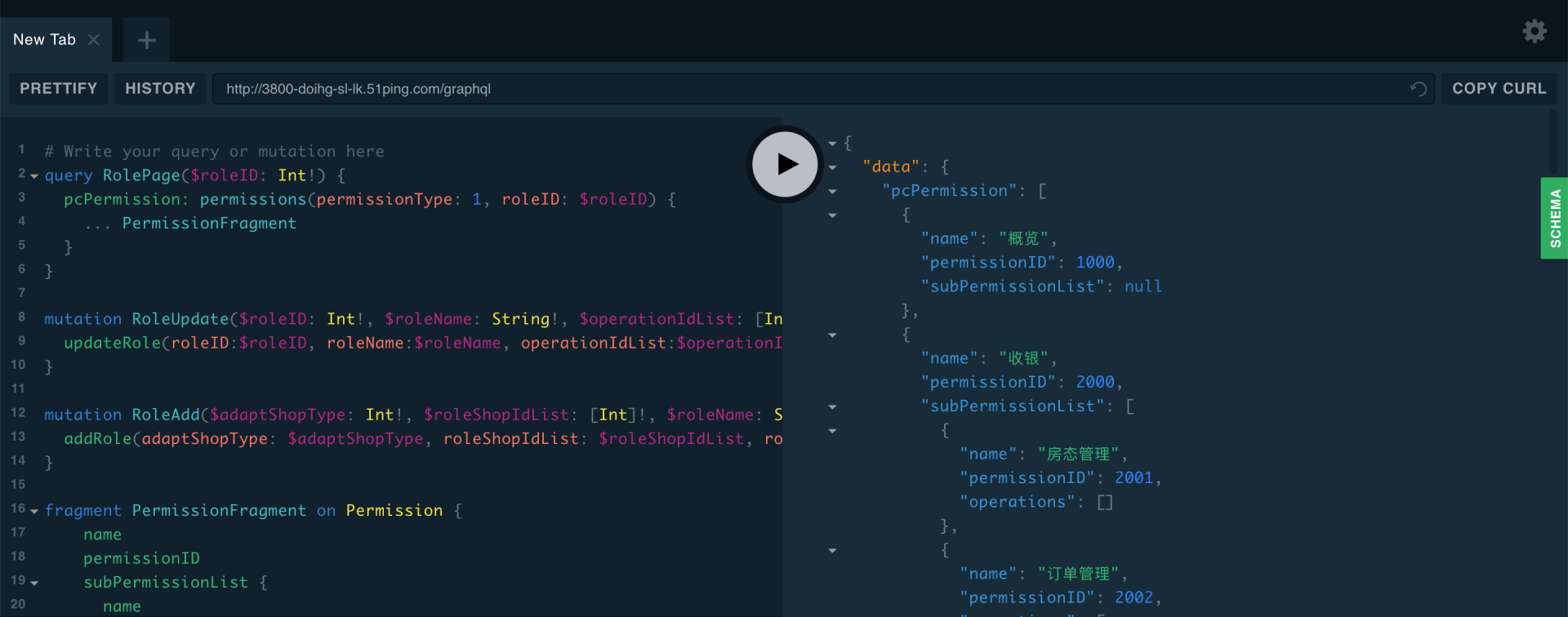
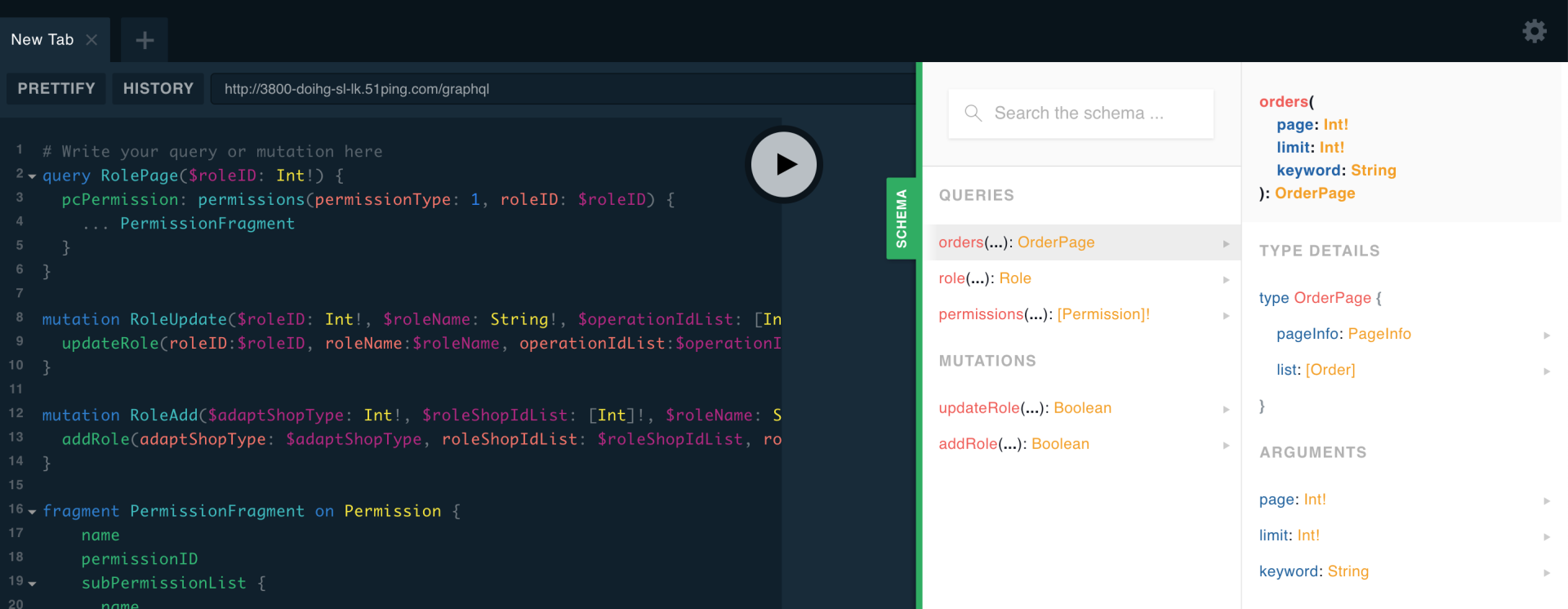
在我们项目中,我们挑选了一个页面进行重构。这个页面加载的时候会重复调用某几个接口,并且只是不同的参数组合,而且需要等待这些接口都返回之后才可以正常展示
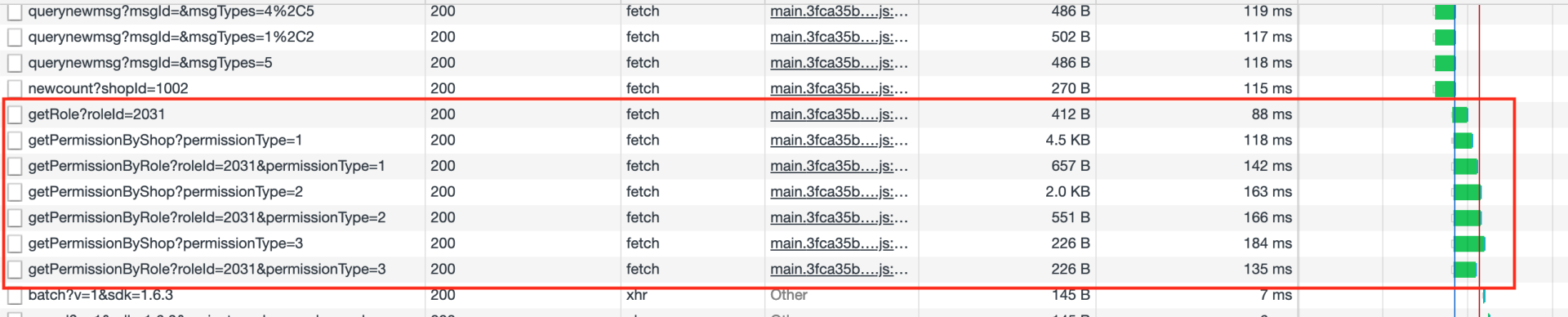
而且原先返回的数据结构,基本是后端的数据模型,返回了很多前端不会用到的字段,非常冗余。
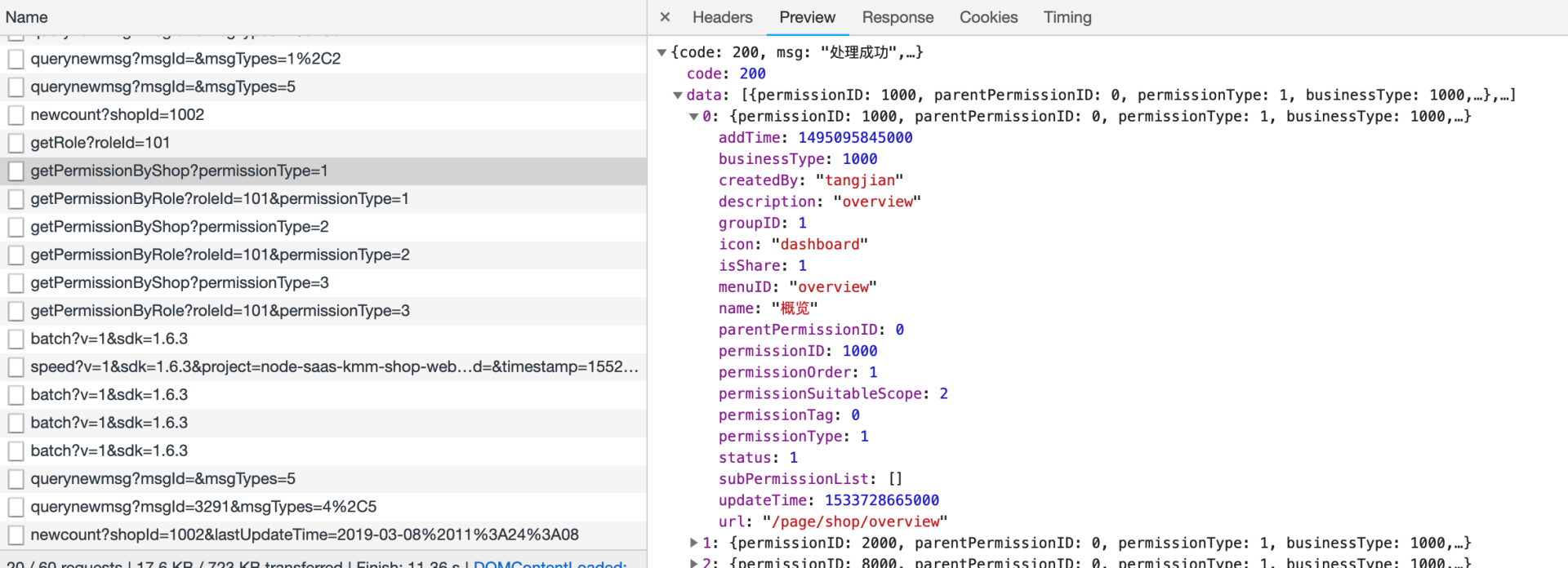
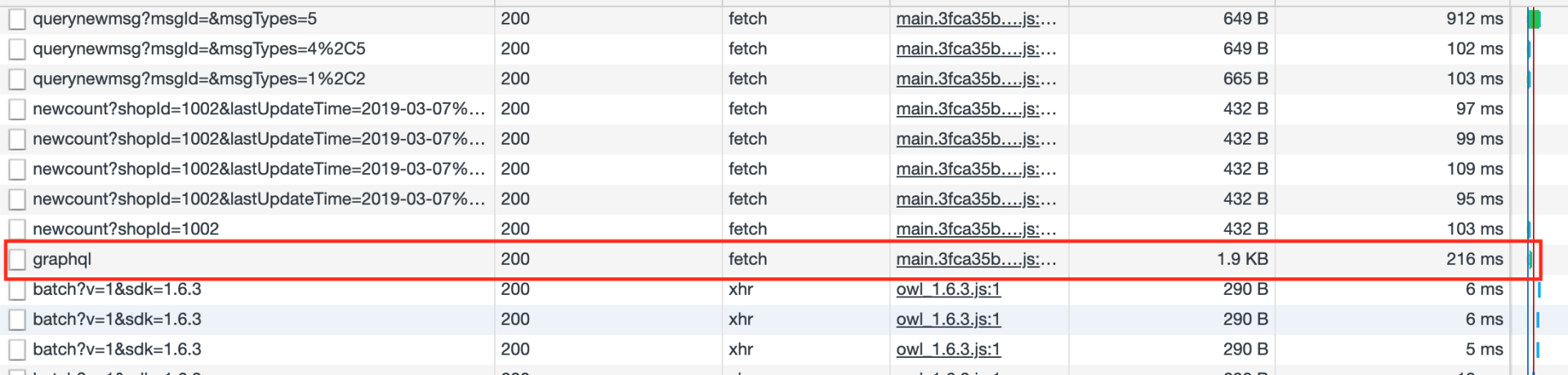
然后我们进行了重构,将这些RESTfull接口通过 GraphQL 进行集成,只需要通过一次请求,就完成了上述七个接口的工作
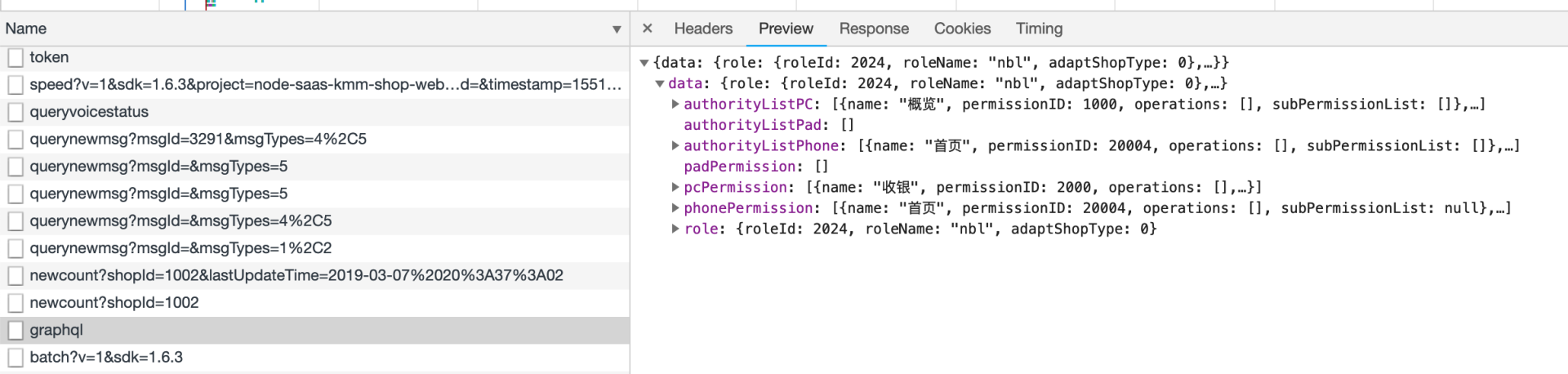
并且只会返回前端需要的字段,再也没有冗余字段。
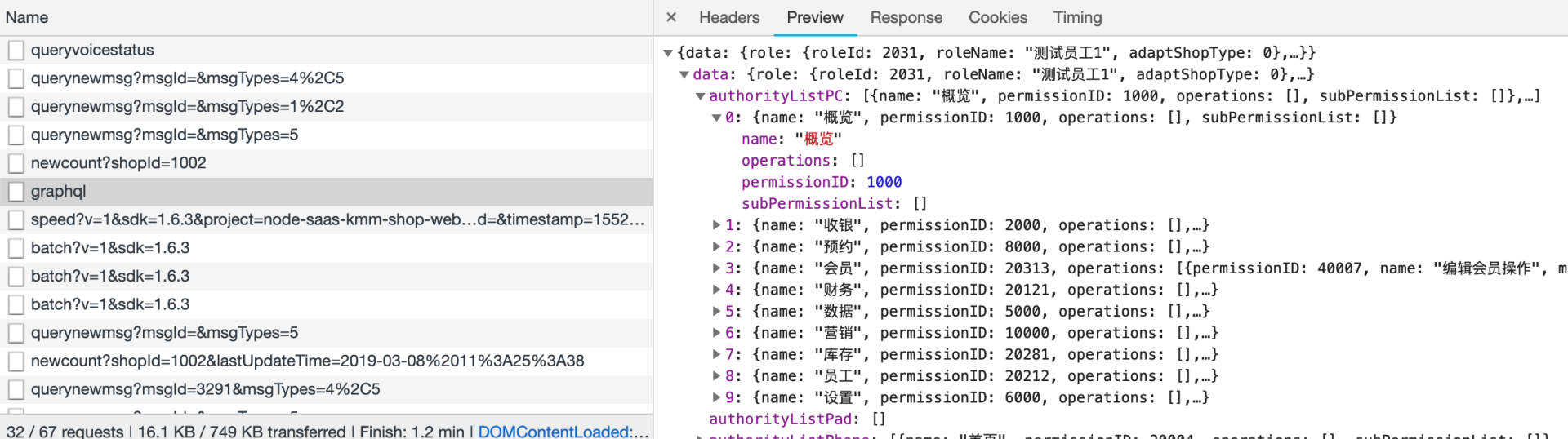
集成了七个 RESTfull 接口功能的单个 GraphQL 请求的耗时,只比单个 RESTfull 请求的多了几十毫秒。
总结
GraphQL可以将多个网络请求接口合并成一个,非常适合于单个页面需要调用多个 RESTfull 接口的场景,比如财务报表页面;
GraphQL由于只提供单个对外接口,调用方如果聚合的接口越多,耗时会增加的越多,需要考虑好粒度,可以通过dataloader进行优化,但无法彻底解决性能问题;
Schema的设计需要谨慎,避免节点冲突和Schema结构混乱,以及产生性能问题;
GraphQL是一个集中式的管理,如果业务系统强依赖的话,需要考虑如何解决单点故障,建议GraphQL只做分发,尽量轻薄;
GraphQL虽然提供 mutation 类型来支持修改数据,但从语法的支持上还是比较古怪,且使用场景上并发多个Post请求的操作也比较少见,个人感觉更适合于查询的场景。
参考资料
https://cloud.tencent.com/developer/article/1354447
http://jerryzou.com/posts/10-questions-about-graphql/
https://ithelp.ithome.com.tw/articles/10200678?sc=hot
https://draveness.me/graphql-microservice